Internet of Things (Интернет вещей) означает сеть физических или виртуальных предметов (вещей) подключенных напрямую или опосредованно к интернету и взаимодействующие между собой и/или с внешней средой посредством сбора данных и обмена данных поступающих со встроенных сервисов. Интернет вещей (IoT) дает компаниям и организациям возможность контролировать удаленно расположенные «дешевые» вещи /объекты ...
Интернет вещей (Internet of Things) - Интернет вещей означает сеть физических или виртуальных предметов (вещей) подключенных напрямую или опосредованно к интернету и взаимодействующие между собой и/или с внешней средой посредством сбора данных и обмена данных поступающих со встроенных сервисов. Интернет вещей (IoT) дает компаниям и организациям возможность контролировать удаленно расположенные...

Группа Arenadata — ведущий российский разработчик ПО и лидер по количеству коммерческих внедрений на рынке систем управления и обработки данных. Группа представлена во всех ключевых нишах рынка и занимает лидирующие позиции в большинстве продуктовых категорий. Эксперты Arenadata вносят существенный вклад в развитие глобальных Open Source проектов. Arenadata среди мирового сообщества...
Apache Hive - это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код...
Разграничение доступа на основе атрибутов (Attribute-Based Access Control, ABAC) — модель контроля доступа к объектам, основанная на анализе правил для атрибутов объектов или субъектов, возможных операций с ними и окружения, соответствующего запросу. Системы управления доступом на основе атрибутов обеспечивают мандатное и избирательное управление доступом. Рассматриваемый вид разграничения доступа дает возможность создать огромное количество комбинаций условий...

Data Provenance (происхождение данных) — это документированная история данных с момента их создания до текущего состояния. Она включает в себя все метаданные, описывающие источники, процессы, преобразования и перемещения, которые данные претерпели. Представьте себе родословную ценного произведения искусства: она подтверждает его подлинность, описывает всех владельцев и реставрации. Точно так же Data...
Apache Kafka – это высокопроизводительная распределенная потоковая платформа с открытым исходным кодом, разработанная изначально в LinkedIn, которая позволяет приложениям публиковать, подписываться, хранить и обрабатывать потоки записей в реальном времени, обеспечивая при этом высокую пропускную способность, масштабируемость и отказоустойчивость для широкого круга сценариев использования, включая обработку больших данных и микросервисные архитектуры....
Churn Rate (уровень оттока клиентов) - индикатор, показывающий процент пользователей, которые перестали пользоваться приложением (сервисом) или перестали быть вашим клиентом в течение рассматриваемого периода. Для уменьшения оттока клиентов используют таргетированные маркетинговые кампании для удержания клиентов с помощью персональных бонусов, скидок и предложения. Для успешной компании уровень оттока клиентов (Churn Rate) должен...
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...
Искусственная классификация - разделение объектов по внешнему признаку для придания множеству исследуемых предметов (процессов, явлений) нужного порядка. Вообще в Data Mining, Data Science и машинном обучении (Machine Learning) в частности, искусственная классификация используется в рамках подготовки данных к моделированию, на этапе формирования датасета. Например, Data Scientist может заниматься искусственной классификацией...
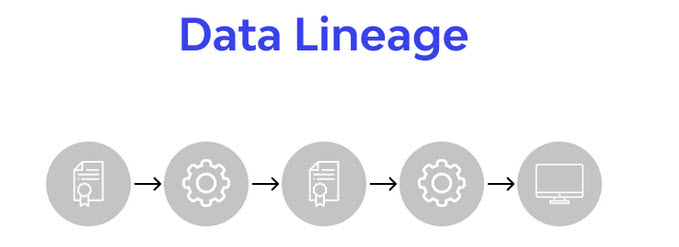
Data Lineage (линейность данных) — это процесс отслеживания, визуализации и понимания пути данных от их источника до конечного потребителя. Он включает в себя все точки остановки и трансформации на этом пути, отвечая на ключевые вопросы: откуда пришли данные, что с ними произошло и куда они направляются. Если представить все данные...
Машинное обучение (Machine Learning) — класс методов искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться
Естественная классификация - разделение (или, наоборот, группировка) предметов и явлений по существенным признакам, характеризующим их внутреннюю общность. В отличие от искусственной классификации, которая сосредоточена на внешних признаках, естественная больше ориентируется на внутреннее содержание исследуемого предмета. В частности, группировка предмета со схожими по сути (овощи, посуда, техника) - это естественная классификация....
отношение объектов, неправильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении