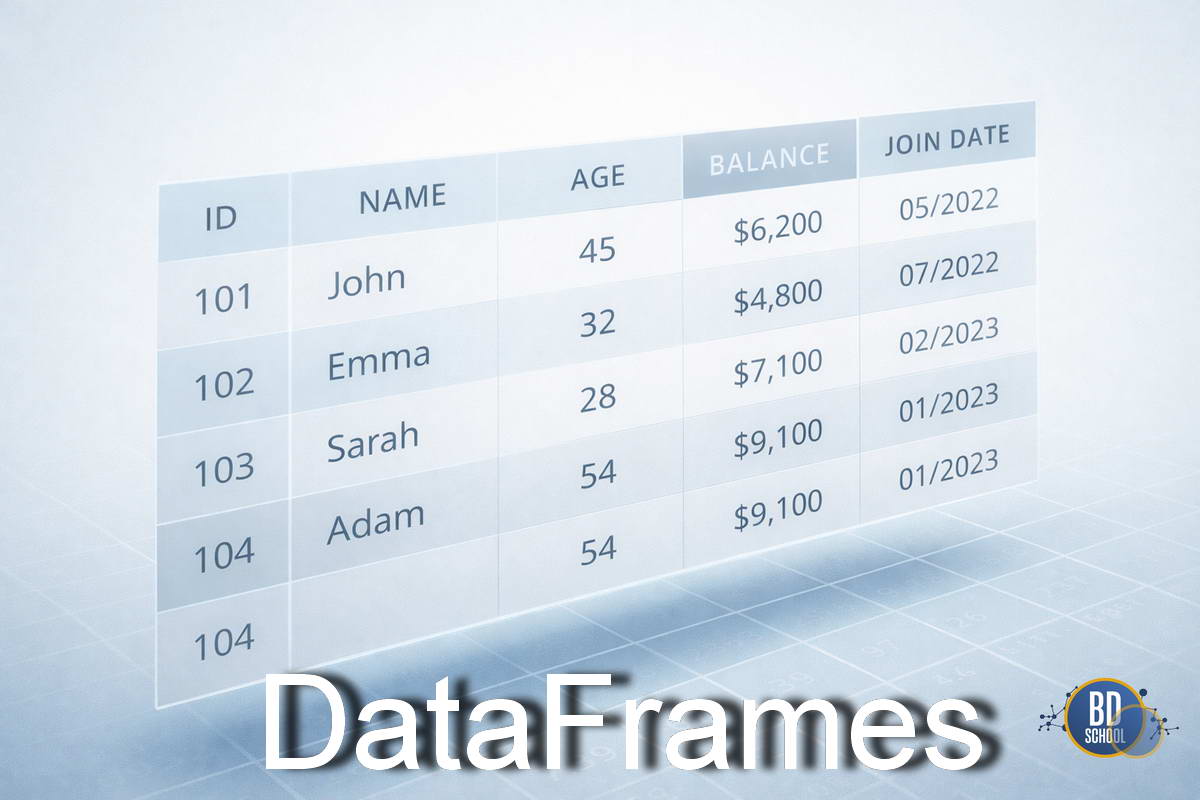
DataFrame — это табличная структура данных с именованными столбцами и индексами строк, предназначенная для удобного хранения, преобразования и анализа структурированных данных в аналитических и научных вычислениях. Представьте себе лист Excel, но с возможностью программного управления и обработки миллионов строк за секунды. Это основной объект для манипуляции данными в языке...

RBAC (Role-Based Access Control), или Управление доступом на основе ролей, - это фундаментальный отраслевой стандарт для управления правами доступа в IT-системах. Суть RBAC проста: вместо того чтобы назначать права доступа (например, "чтение таблицы X") напрямую каждому отдельному пользователю ("Ивану", "Петру", "Сервисному-Аккаунту-1"), вы сначала создаете Роль (например, "Аналитик"). Вы даете все...

NoSQL (Нереляционные базы данных) - это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL ("Not Only SQL") означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных. В отличие от классического подхода, где структура данных...

DevOps (DEVelopment OPeration) – это набор практик для повышения эффективности процессов разработки (Development) и эксплуатации (Operation) программного обеспечения (ПО) за счет их непрерывной интеграции и активного взаимодействия профильных специалистов с помощью инструментов автоматизации. Девопс позиционируется как Agile-подход для устранения организационных и временных барьеров между командами разработчиков и других участников жизненного...

Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного...

Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1]. История появления Спарк и сравнение с Apache Hadoop Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики....

Apache Cassandra – это нереляционная отказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, представленных в виде хэша. Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду Apache Software Foundation в 2009 [1]. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она...

Data Lake (озеро данных) — это логическая совокупность репозиториев данных, предназначенных для хранения и анализа больших данных в их исходном формате. В отличие от традиционного понимания централизованного хранилища, Data Lake может быть распределенным по множеству физических местоположений, включая облачные платформы, on-premises инфраструктуру или гибридные среды. Концепция озера данных...

ClickHouse – колоночная реляционная СУБД с открытым исходным кодом от компании Яндекс для быстрой обработки аналитических SQL-запросов на структурированных больших данных (Big Data) в режиме реального времени.

Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска. Назначение и основные функциональные возможности Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить,...
Ввод и вывод в Apache Spark Apache Spark имеет простые, удобные и универсальные механизмы ввода вывода. С их помощью просто "читать" и "писать" файлы различных форматов (поддерживаются текстовые файлы, CSV, JSON, Parquet, ORC), а также работа с базами данных (через JDBC). Spark может использовать общие с Hive метаданные, тем самым...
Segmentation image – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении класса (раскраска) каждого пикселя на цифровом изображении или на каждом кадре видеопотока. Пример кода вы можете посмотреть на GitHub MachineLearningIsEasy...
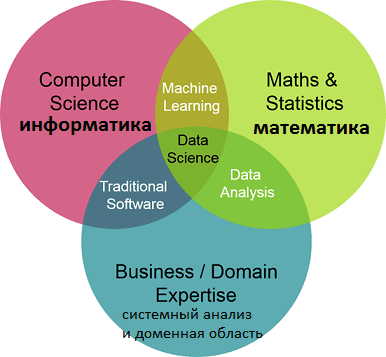
Data Science – это наука о данных, объединяющая разные области знаний: информатику, математику и системный анализ. Сюда входят методы обработки больших данных (Big Data), интеллектуального анализа данных (Data Mining), статистические методы, методы искусственного интеллекта, в т.ч машинное обучение (Machine Learning). DS включает методы проектирования и разработки баз данных и прикладного...
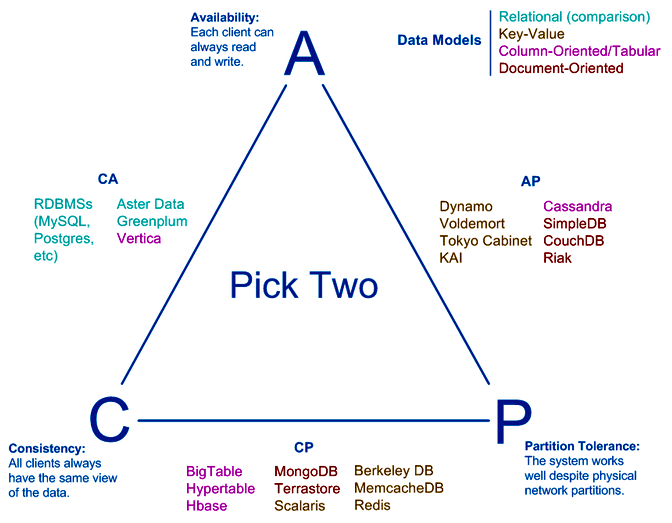
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...

Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано...

Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала...
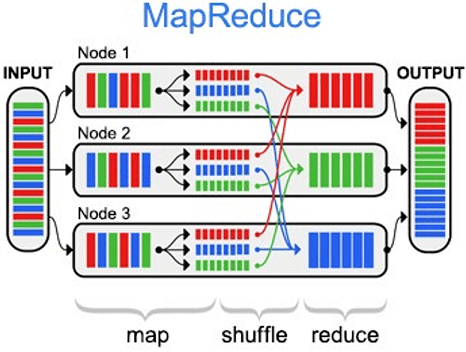
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1]. Назначение и области применения MapReduce можно по праву назвать главной технологией...

Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure. Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года,...
Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга...