DataFrame — это табличная структура данных с именованными столбцами и индексами строк, предназначенная для удобного хранения, преобразования и анализа структурированных данных в аналитических и научных вычислениях. Представьте себе лист Excel, но с возможностью программного управления и обработки миллионов строк за секунды. Это основной объект для манипуляции данными в языке...

NoSQL (Нереляционные базы данных) - это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL ("Not Only SQL") означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных. В отличие от классического подхода, где структура данных...

Apache Airflow — это открытая платформа для программного создания, планирования и мониторинга рабочих процессов. Изначально созданная в стенах Airbnb, она быстро эволюционировала в индустриальный стандарт для оркестровки сложных конвейеров данных. Важно сразу провести черту: Apache Airflow не обрабатывает данные самостоятельно, как Apache Spark, а выступает в роли «дирижёра»...

Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного...

Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1]. История появления Спарк и сравнение с Apache Hadoop Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики....

Kudu – это колоночное хранилище данных в экосистеме Apache Hadoop, нереляционная СУБД (NoSQL) с открытым исходным кодом от компании Cloudera для оперативной аналитики быстро меняющихся данных в режиме реального времени. Назначение, история разработки и развития Основное назначение Apache Kudu состоит в заполнении аналитического разрыва между 2-мя движками хранения данных Apache...
Ввод и вывод в Apache Spark Apache Spark имеет простые, удобные и универсальные механизмы ввода вывода. С их помощью просто "читать" и "писать" файлы различных форматов (поддерживаются текстовые файлы, CSV, JSON, Parquet, ORC), а также работа с базами данных (через JDBC). Spark может использовать общие с Hive метаданные, тем самым...
Spark SQL - это часть Spark Structured API, с помощью этого API Вы можете работать с данными так, как будто Вы работаете с SQL сервером. API работает в обе стороны: результат выполнения SQL запроса - dataframe, в обратном направлении - регистрация существующего dataframe, как таблицы (к которой можно выполнить SQL...

Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано...

Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала...
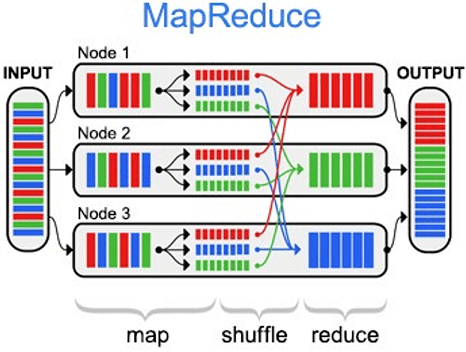
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1]. Назначение и области применения MapReduce можно по праву назвать главной технологией...

Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure. Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года,...
Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга...

Avro – это линейно-ориентированный (строчный) формат хранения файлов Big Data, активно применяемый в экосистеме Apache Hadoop и широко используемый в качестве платформы сериализации. Как устроен формат Avro для файлов Big Data: структура и принцип работы Avro сохраняет схему в независимом от реализации текстовом формате JSON (JavaScript Object Notation), что облегчает...
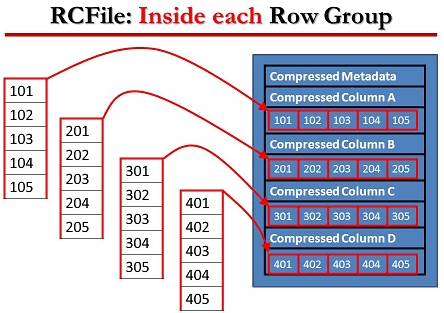
RCFile (Record Columnar File) – гибридный многоколонный формат записей, адаптированный для хранения реляционных таблиц на кластерах и предназначенный для систем Big Data, использующих MapReduce. Этот формат для записи больших данных появился в 2011 году на основании исследований и совместных усилий Facebook, Государственного университета Огайо и Института вычислительной техники Китайской академии...

ORC (Optimized Row Columnar) – это колоночно-ориентированный (столбцовый) формат хранения Big Data в экосистеме Apache Hadoop. Он совместим с большинством сред обработки больших данных в среде Apache Hadoop и похож на другие колоночные форматы файлов: RCFile и Parquet. Формат ORC был разработан в феврале 2013 года корпорацией Hortonworks в сотрудничестве...

Apache Parquet - это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом...

HDInsight - это корпоративный сервис с открытым кодом от Microsoft для облачной платформы Azure, позволяющий работать с кластером Apache Hadoop в облаке в рамках управления и аналитической работы с большими данными (Big Data). Экосистема HDInsight Azure HDInsight – это облачная экосистема компонентов Apache Hadoop на основе платформы данных Hortonworks Data Platform...
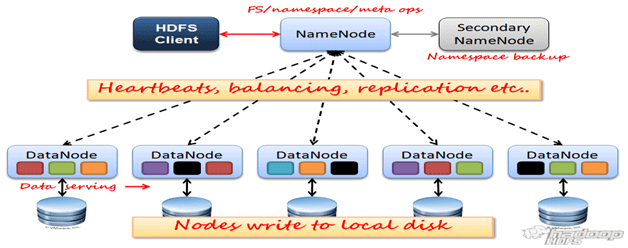
HDFS (Hadoop Distributed File System) — распределенная файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера [1], который может состоять из произвольного аппаратного обеспечения [2]. Hadoop Distributed File System, как и любая файловая система – это иерархия каталогов с...