
Сегодня разберем опыт австралийской ИТ-компании hipages по построению самообслуживаемого ETL-конвейера с Apache Airflow и Amazon Athena, призванного обеспечить высокое качество данных и облегчить дата-инженерам управление информационными активами. Изящное решение сложных проблем управления данными с примерами SQL-запросов к корпоративному Data Lake на AWS S3. Что не так с монолитной архитектурой платформы данных...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...
Иногда в распределенных системах требуется строгий порядок событий, т.е. сообщений или записей с полезными данными и состоянием, который должен поддерживаться между продюсерами и потребителями в конвейере их обработки. Например, чтобы сохранить корректный порядок транзакций для правильного расчета остатков по счетам. Читайте далее, как это реализовать в Apache Kafka. Настройка продюсера...
Благодаря возможности написать собственный Python-код для операторов и задач DAG’ов, Apache Airflow позволяет разработчикам Data Flow и инженерам данных создавать сложные и эффективные конвейеры пакетной обработки данных. Обеспечить надежность этого многообразия поможет качественное тестирование пользовательского кода. Рассмотрим примеры и рекомендации по написанию модульных тестов. Зачем тестировать DAG AirFlow? Модульные тесты...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...
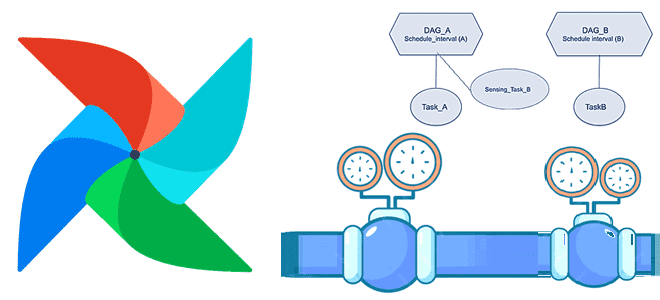
Мы уже писали про датчики или сенсоры - особый тип операторов Apache AirFlow, предназначенных для ожидания какого-то события. Сегодня рассмотрим практический пример обучения дата-инженеров и разработчиков по использованию внешнего сенсора в рамках типовой задачи дата-инженерии по организации ETL/ELT-процессов при поэтапной загрузке данных в DWH для OLAP-систем. Постановка задачи: поэтапная загрузка...
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...